Tell me about the ARC Raiders project.
Scrappy TR — ARC Raiders Fan Project
Scrappy the Rooster is a full-stack fan project for ARC Raiders, a co-op PvE extraction shooter by Embark Studios. It's a data pipeline that scrapes community wiki content, an API that serves it, and a React UI for browsing game items like loot, crafting recipes, and breakdown costs.
Built around May–June 2025 using Windsurf and ChatGPT as AI pair programmers, similar to how I built Suno Shuffle. It was also the first project where I used AI to help manage AWS infrastructure (DynamoDB tables, API Gateway, Lambda), which stuck as a habit.
GitHub: Data Pipeline · API · UI
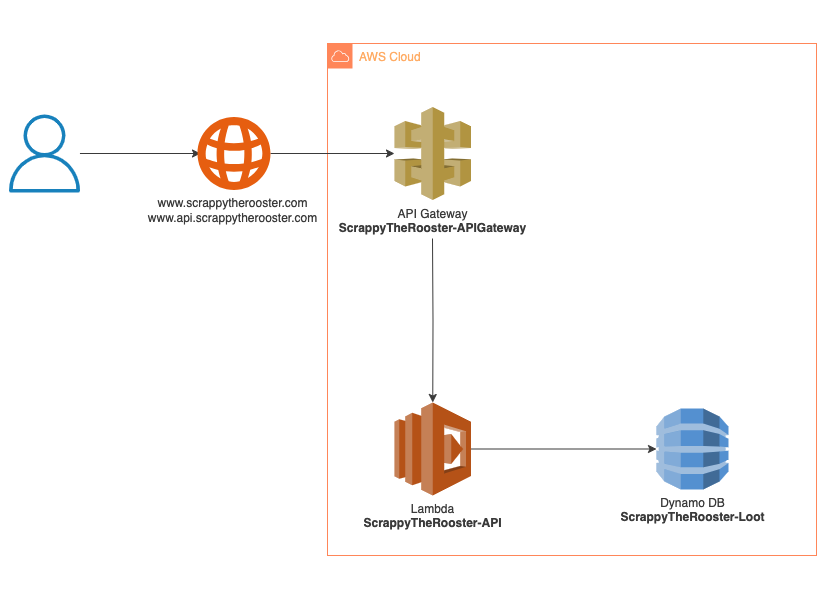
Three Parts
1. Data Pipeline
- Python Scrapy spiders that crawl the ARC Raiders community wiki
- Extracts loot, crafting recipes, breakdown costs, and item relationships
- Normalizes messy wiki data and pushes structured records to DynamoDB
2. REST API
- Serves game data from DynamoDB via API Gateway
- Endpoints for items, recipes, loot tables
- Example:
GET /loot/Wiresreturns rarity, crafting uses, recycle outputs
3. React UI
- Browse and search the ARC Raiders item catalog
- Filter by category, rarity, crafting requirements
- Built with React 18, TypeScript, Tailwind CSS, Vite
Tech Stack
Python, Scrapy, AWS DynamoDB, API Gateway, Lambda, React, TypeScript, Tailwind CSS
Scraping Challenges
The game hadn't officially launched yet — all the data was community-sourced from beta test phases, making the whole project a moving target. The wiki itself was inconsistent: some items had data in HTML tables, others used unordered lists for the same fields. Items had complex relationships (crafting inputs, breakdown outputs, cross-references) that weren't structured uniformly, and the data was sometimes incomplete or contradictory. The spiders needed a lot of defensive parsing and normalization logic to produce clean, consistent records for DynamoDB.
Status
Shelved. Another community project gained more traction and stayed more up-to-date as the game evolved through test phases. The live site was scrappytherooster.com (now defunct). Good end-to-end exercise though — scraping, API design, and a React frontend all wired together on AWS serverless.